About
About FluidOne
Meet The Team
NPS & Service
Clients & Case Studies
Press
Careers
Sectors
Professional Services
Finance & Insurance
Transport & Logistics
Manufacturing
Construction
Retail
Other
Connected Cloud Solutions
SD-WAN & Connectivity
SASE (Secure Access Service Edge)
Enterprise IT
Business IT
Cyber Security
Unified Communications & Contact Centre
Mobile & IoT
Products
Connectivity Via Platform One
PSTN Switch Off
Business Broadband
Leased Line
Wide-Area-Network (WAN)
LAN & Wi-Fi
SD-WAN
SASE
Business 4G Broadband
Public Cloud Access
SOGEA & SOADSL
Business IT
Modern Workplace
Microsoft Office 365 & Teams
IT Security
IT Managed Services
Cloud Hosting
Backup as a Service
Disaster Recovery
LAN & Wi-Fi
Hosting & Colocation
Enterprise IT
IT Managed Services
Transformation
Mobile & IoT
Mobile Deployment Services
Mobile Handsets
Mobile Security
IoT, M2M & Roaming Sim Cards
Mobile Device Management Software
Business Mobile Plans & Solutions
F1-Sim
Unified Communications
SIP Trunk Solutions
8×8 Unified Communications
Mitel System Maintenance
Contact Centre
Microsoft Teams Voice
Cyber Security
Cyber Assessments
Consulting
Cyber Executives
Security Operations Centre
Monitor & Detection
Protection
Response
Training
Penetration testing
Partners
Build Your Business on FluidOne
Become A Partner
Dash Portal
Resources
All Resources
Blog
Case Studies
Datasheets
Events
Guides
Infographics
News
Offers
Other PDFs
Webinars
Video
Support
Contact
Customer Login
About
About FluidOne
Meet The Team
NPS & Service
Clients & Case Studies
Press
Careers
Sectors
Professional Services
Finance & Insurance
Transport & Logistics
Manufacturing
Construction
Retail
Other
Connected Cloud Solutions
SD-WAN & Connectivity
SASE (Secure Access Service Edge)
Enterprise IT
Business IT
Cyber Security
Unified Communications & Contact Centre
Mobile & IoT
Products
Connectivity via Platform One
PSTN Switch Off
Business Broadband
Leased Line
Wide-Area-Network (WAN)
LAN & Wi-Fi
SD-WAN
SASE
Business 4G Broadband
Public Cloud Access
SOGEA & SOADSL
Enterprise IT
IT Managed Services
Transformation
Business IT
Modern Workplace
Microsoft Office 365 & Teams
IT Security
IT Managed Services
Cloud Hosting
Backup as a Service
Disaster Recovery
LAN & Wi-Fi
Hosting & Colocation
Mobile & IoT
Mobile Deployment Services
Mobile Handsets
Mobile Security
IoT, M2M & Roaming Sim Cards
Mobile Device Management Software
Business Mobile Plans & Solutions
F1-Sim
Unified Communications & Contact Centre
SIP Trunk Solutions
8×8 Unified Communications
Mitel Phone System Maintenance
Contact Centre
Microsoft Teams Voice
Cyber Security
Cyber Assessments
Consulting
Cyber Executives
Security Operations Centre
Monitor & Detection
Protection
Response
Training
Penetration testing
Partners
Build Your Business on FluidOne
Become A Partner
Dash Portal
Resources
All Resources
Blog
Case Studies
Datasheets
Events
Guides
Infographics
News
Offers
Other PDFs
Webinars
Video
Support
Contact
Resources
Copilot for SMBs
Guide
Download
Copilot for Microsoft 365
Guide
Downlaod
From Data to Decision
Infographics
Open PDF
Are you in the cloud?
Infographics
Open PDF
LEO communications and the opportunities for businesses
Infographics
Open PDF
PSTN: 4 Steps to Migration Success
Infographics
Open PDF
Our Cyber Security Breakfast Briefing
Video
Watch Now
An Introduction to the Connected Cloud
Video
Watch Now
Exploring Lookout Mobile Endpoint Security
Webinar
Watch Now
Cyber Insurance: The Changing Markets
Webinar
Watch Now
MobileFlex by FluidOne Datasheet
Datasheet
Open PDF
A14 Delivery Team
Case Study
Download
Accent
Case Study
Download
Adata
Case Study
Download
Attivo Group
Case Study
Download
Barratt Developments
Case Study
Download
Carluccio's
Case Study
Download
Cresta World Travel
Case Study
Download
Crowe Clark Whitehill
Case Study
Download
DCL
Case Study
Download
Dennis Eagle
Case Study
Download
Digraph
Case Study
Download
EU Bank Real Estate
Case Study
Download
FSI Cloud
Case Study
Download
Griffiths
Case Study
Download
Krispy Kreme
Case Study
Download
Land Securities
Case Study
Download
McLaren
Case Study
Download
Metro Bank
Case Study
Download
Murray Volkswagen
Case Study
Download
Nemesis
Case Study
Download
Norville
Case Study
Download
O2
Case Study
Download
QVIS
Case Study
Download
Princes
Case Study
Download
Regtransfers
Case Study
Download
Ringway Jacobs
Case Study
Download
Saville Group
Case Study
Download
Synergy Associates
Case Study
Download
TM Lewin
Case Study
Download
UK Distillery Firm
Case Study
Download
University of Surrey
Case Study
Download
Exploring the interconnected workplace
Guide
Open PDF
Why your business needs to digital voice
Guide
Open PDF
Why you shouldn’t wait to go digital
Guide
Open PDF
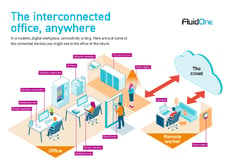
The interconnected office, anywhere
Guide
Open PDF
The digital transformation checklist
Guide
Open PDF
The A to Z of digital transformation
Guide
Open PDF
PSTN Retirement FAQs
PDF
Open PDF






.png?height=162&name=FluidOne%20Email%20Headings%20(12).png)